More projects in this category

AI Content Rewriter
Content output increased 5x. Organic traffic grew 120% in 6 months.
View Project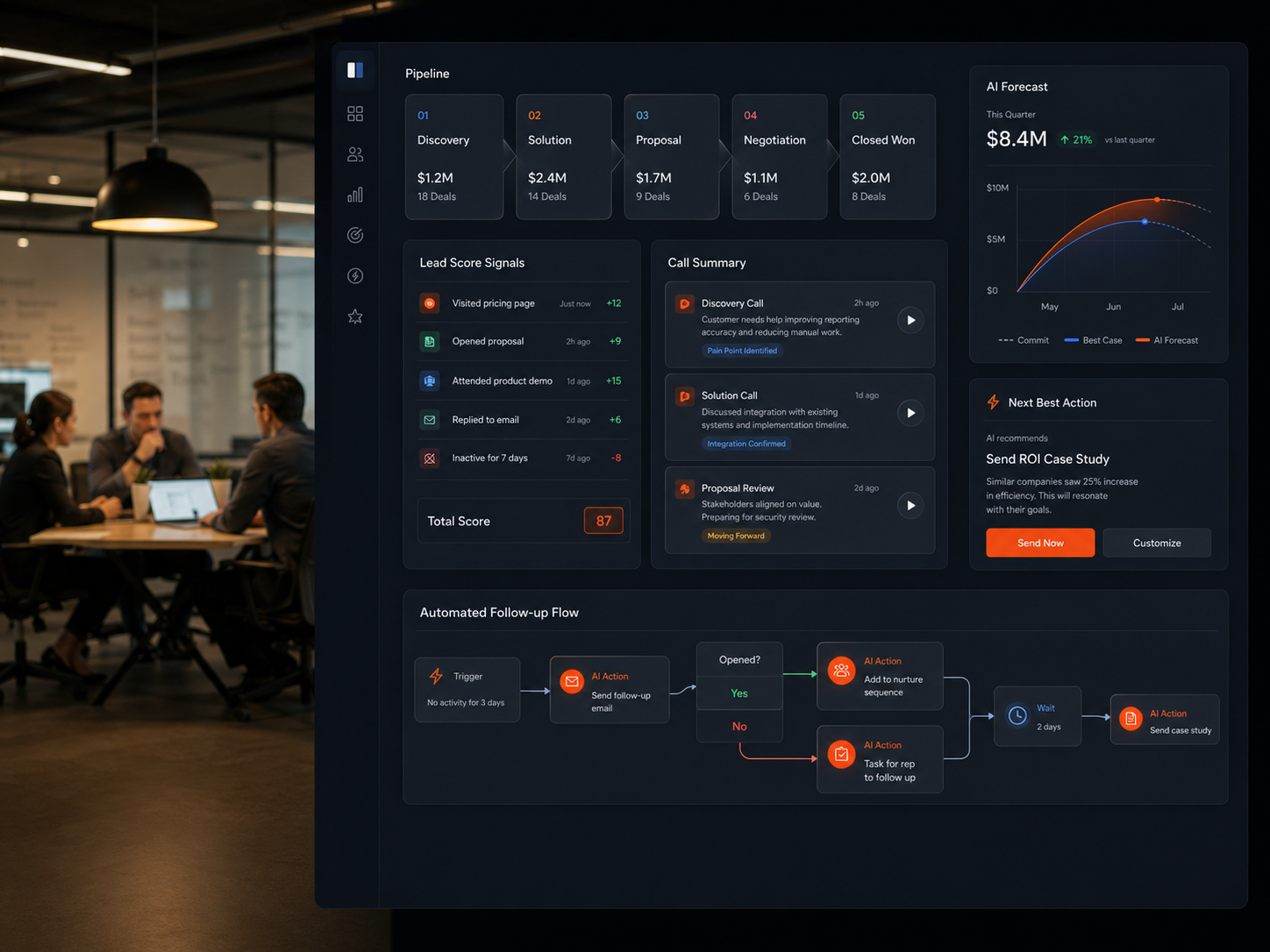
Traffic Analysis Dashboard
Ad spend efficiency improved 55%. ROI visibility went from monthly reports to real-time.
View Project
Big String AI
Users process entire codebases and document sets in single queries. API adopted by 200+ developers.
View Project